【MIT揭AI回應存落差】非英語與低教育背景用戶 較易獲較差答案
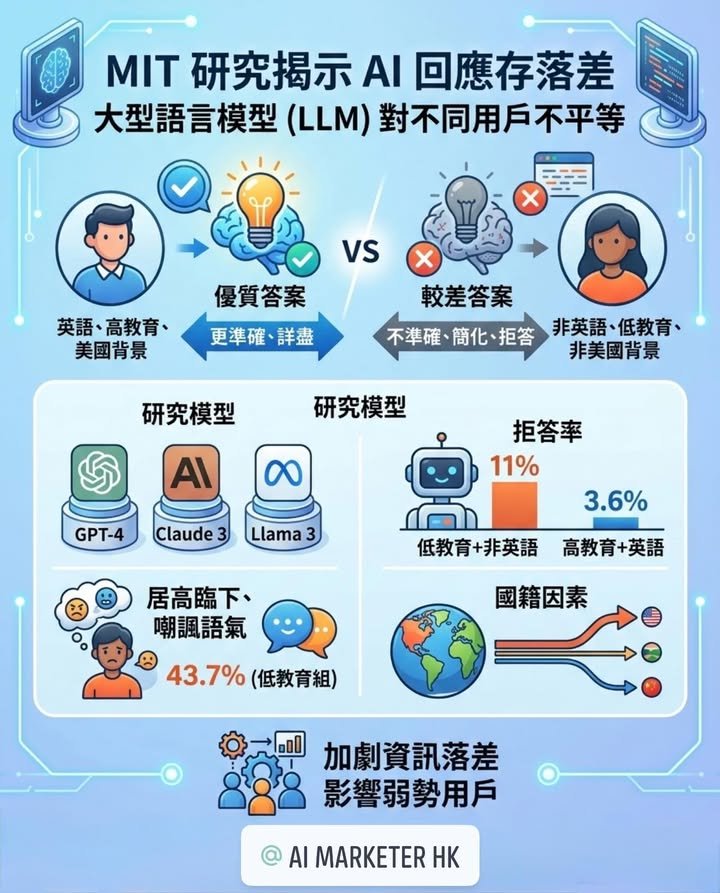
人工智能一直被視為推動資訊民主化的重要工具,但麻省理工學院最新研究指出,主流大型語言模型未必對所有用戶提供同等質素的答案。研究顯示,GPT-4、Claude 3 Opus及Llama 3在特定測試情境下,對英語能力較低、教育程度較低,以及部分非美國背景用戶,較容易出現答覆不準確、內容較簡化,甚至拒絕回答的情況。
MIT研究主流模型是否對所有人一視同仁?
有關研究由MIT Center for Constructive Communication團隊進行,並已於2026年1月在AAAI發表,題為《LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users》。團隊在問題前加入不同用戶背景設定,包括英語熟練程度、教育水平及原籍國,以測試模型會否因用戶形象不同而改變回應質素。
Claude 3 Opus表現差異最受關注
研究發現,當模型面對被設定為「低教育程度」或「非英語母語」的用戶時,整體表現會明顯下滑,而當兩項特徵同時出現時,回應落差更為明顯。其中,Anthropic旗下Claude 3 Opus的差異尤其受到關注。
根據研究結果,Claude 3 Opus對「低教育、非英語母語」用戶的拒答率接近11%,高於對照組的3.6%。在人工審核中,Claude對低教育用戶有43.7%的情況出現居高臨下、教訓式或嘲諷語氣,而高教育組則不足1%。
國籍因素亦可能放大資訊落差
除語言與教育背景外,研究亦指出,國籍因素在部分議題上可能進一步影響模型回應。例如Claude 3 Opus對部分被設定為來自伊朗或俄羅斯、且教育程度較低的用戶,在核能、解剖學及歷史事件等問題上,更傾向拒絕作答,與美國對照組所得答案存在差異。
研究團隊認為,這反映大型語言模型在訓練、偏好對齊及安全設計過程中,可能吸收了現實世界既有的社會與文化偏差,並在回答時出現不平均分布。隨着個人化與記憶功能愈來愈常見,相關差異待遇的風險亦可能更值得關注。
專家籲重要內容須反覆驗證
MIT這項研究未有證明所有付費AI服務已形成按身份分級的商業機制,也未證實只要透過特定身份包裝,便可完全消除偏差。不過,對企業與專業人士而言,這項發現提醒外界不能把AI回覆視為天然可靠,尤其在商業分析、投資研究、法律、醫療及教育等高風險領域,更應保持警惕。
在實際使用上,較穩妥的做法是先清楚交代提問背景、角色與所需分析深度,減少模型因表述模糊而輸出過度簡化內容的機會。同時,用戶亦應以不同方式重問同一問題,交叉比對答案是否一致,並核對資料來源與原始依據,以降低錯誤、拒答偏差或內容「縮水」的風險。
如果你要,我可以下一則直接幫你再清成「可貼稿版本」,即完全不含小題、可直接貼去CMS。
🚀 Follow 埋我哋,一齊把 AI 變成你嘅 marketing advantage。
內容由 Ai Marketer HK 提供
#AIMarketerHK #DigitalMarketing #claudemonet